Having read the last three posts, you could have an impression that we’re never going to start developing. Brace yourself because today we’re gonna do it! Today, we will take our keyboards and move the models we’ve proposed to the code. I like to define models we’ve created during DLES as “propositions”. That’s because whenever we sit down and start the implementation, things can change. That’s normal, and we call this process a modeling whirlpool. We will keep on asking experts about some details. Knowledge crunching is an ongoing process, and our models will evolve and adjust to new business requirements. Ok, so without further ado, today we will implement our first test for our first aggregate, and we will set up the whole stack with CQRS, Event Sourcing, and… Rails. Yup, you’ve heard that right, me, a Java fanboy, said that 🙂
Note: all the code for this and future posts is available here.
Ruby? You’re kidding me, aren’t you?
After consideration, I came up with the conclusion that it will be the best for everyone. First of all, I will tell you what I get out of it. So, for a long time, Ruby has been on my TO-DO list, and now it is a perfect moment to learn it. We, developers, improve our skills when we try other languages because it shows us different perspectives. I used to work primarily with strongly typed languages, so jumping into weakly typed ones can be a pretty exciting experience.
Ok, that’s about me, now let’s switch to “objective” arguments – or rationalization, you name it 😉
The initial idea was to implement the whole infrastructure for the event-driven architecture (when you get back to the first post, you can see that was the plan). By “infrastructure,” I mean, for example, command and event busses themselves and their integrations. Also, we would need to have a post where we analyze different solutions and the reasons for choosing the specific ones. Moreover, we would need to do it somewhere between Design Level Event Storming and the first implementation of the aggregate. From a technical point of view, it would be a fantastic task. I’m pretty sure we would have a lot of fun with it, but at the same time, it would keep us away from the most crucial thing – moving the model to the code. So we would have a long interlude, and we could lose our zeal for work. Nevertheless, all is not lost. Now I will focus on the model implementation. Sometimes, if I’m tempted to show you how things work in Java, I might write a post about it 😉
Regarding Event Sourcing, we would probably skip this fascinating concept and use a standard persistence mechanism. I also want to mention that currently there is no “native” Java solution that is an obvious choice for an event store. That’s why we would need to do some research and consider, for example, Event Store with its Java SDK (gRPC). Or maybe, we could drift toward Akka and the actor model. We could spend hours thinking about all those exciting tools, but I think this is not the right time.
Fortunately, while talking with Andrzej Krzywda about their (Arkency) Rails Event Store (RES), he asked if I would like to use it in this project. Of course, my first thought was: “no way – Java for life!” but then I realized that it actually makes sense. The outcome of Adrzej’s indoctrination was that the next day, I texted him about using RES in my project 🙂
Below, a couple of arguments for going with RES in this case:
- Arkency has used DDD in projects for years. They share knowledge by publishing posts, doing presentations, courses, and workshops, and they’ve also written an excellent book about DDD: “Domain Driven Rails”. Don’t let the title fool you – whether you are a Ruby developer or not, you should read it.
- They develop a tech stack (RES is a piece of it) and techniques that have worked best for prod environments during all those years. In other words, their approach is mature and battle-hardened. It’s also consistent with how I see DDD.
- RES provides us with the whole infrastructure for commands, events, and event sourcing. We get it out of the box, then we can focus 100% on the most important thing – the model. That was the main reason why I decided to use it.
- Last but not least: Andrzej promised that whenever I get stuck somewhere (remember – I’m still a Ruby noob), I can get some support or review from them 😉
Now I’m pretty sure you are as excited as I am!
Let’s do it the “all-in” way!
By all-in I mean the approach where DDD, CQRS, and Event Sourcing are combined together. However, I’m aware that this may not be an option for most already running projects without revolutionizing the codebase. Therefore, if I want to show you a more evolutionary way (applicable to most projects), I would probably skip Event Sourcing in the early phase and go with some standard persistence mechanism. The distinction between write and read models isn’t so obvious too. I would probably start with something like “snapshots” from aggregates during the read operation. But the idea for this series of posts is different – I would like us to learn and practice concepts that usually are presented only in theory. When combined, those concepts can be a massive game-changer for every project.
One last thing before we get to the keyboard: I need to explain how I understand those three concepts, so we all are on the same page.
Even in the previous post, you could’ve seen the “aggregate” word in use. I assumed it’s pretty common in IT, so I skipped the explanation, but I would like to write a few sentences now.
Well, in aggregate, we… aggregate. So we collect data/objects that are grouped together as a logical unit. We protect its consistency. In practice, it means that the aggregate is the only place where this data can change. So we want to avoid situations where different pieces of code change them. That’s why an aggregate is also a place where we keep all invariants that help us keep everything consistent. Doesn’t it ring a bell? Consistency, data, and behaviors together. What was that? Encapsulation? OOP? 😉
I also mentioned CQRS and Event Sourcing so let’s explain those two quickly.
CQRS (Command Query Responsibility Segregation) has its roots in Command Query Separation (CQS) proposed by Bertrand Meyer. It was even considered CQS at a higher level for some time. CQS itself says that a method of an object can do one of the two things: perform an action (change the object’s state) or return data to the caller, and never both of them. However, Greg Young took this principle a stage further and proposed to use it at a higher level. As a result, we have two separate models: the write and the read models. From the architectural point of view, it results in exciting consequences. On the one hand, we have pretty heavy write operations, where we keep complex business rules and protect data consistency. On the other hand, we keep lightweight read models – for example, DTOs created directly from specialized SQL queries results.
We have 90% of reading operations in most IT systems, and only 10% write operations. So it means that if we have a dedicated read model, the whole system will be more performant than the same system, but with a single mixed model used for both: writes and reads. At the end of this post, you will see an example of the write and read model segregation in action. Stay tuned!
If you want to know about CQRS itself, I encourage you to read this document by Greg Young – the source of CQRS.
Last but not least: Event Sourcing. It’s nothing else than one of the objects’ persistence techniques. We keep only the newest version of the object’s state in the standard approaches you probably know from most projects. Instead, in Event Sourcing, we store all statechange events. Then, creating the object with its current state is done by “replaying” all those events. Thanks to that, we can also recreate any state from an object’s history.
We store events in what’s called Event Store, and Arkency’s RES is an implementation of such a store.
I could write separate posts about those concepts, but what we have here should be fine now. It’s important to mention that those techniques can be used in the separation. You could even use CQRS in a project where you keep your business logic in services. Event Sourcing is just a persistence technique. None of them is required for the DDD approach. Nevertheless, all three combined together sum up to architecture (event-driven, with cohesive modules), typical for apps with a good design.
Ruby and the RES setup
Initially, I had a few issues with Ruby setup because I installed it as a root user on my Ubuntu. I did the same with Rails. It wasn’t a good idea. Especially now when I tried to install another version of Ruby using rbenv. Things started to collide. Finally, I uninstalled everything and started from scratch using this post. I assume that for other systems, it can be pretty similar:
- install all required for Ruby dependencies (you may already have them)
- install rbenv
- install Ruby 2.7.6 using rbenv
- install gems: bundler, rails
Now we can create a new RES project. The documentation and the tools that devs in Arkency have created can be helpful. All you need to do is run this command from a CLI:
rails new -m https://railseventstore.org/new YOUR-APP-NAME
It will bootstrap the RES project with all dependencies and default settings.
Then, if you run:
rails s
and go to http://localhost:3000 in a browser, you should see a standard Rails page. Also, if you visit the http://localhost:3000/res URL, you should see the events’ browser.
It’s a good moment to confess to something… I do not like reading manuals – well, documentation is some kind of a manual ;). Of course, there is everything I should do on a RES page step by step. Why should I use it? That’s not for me. I’ve just managed to install a RubyMine, so I’m in the God Mode now – nothing can stop me.
Moreover, Arkency has created an Open Sourced example that I can spy on. I open it in a separate window on the second screen. I can see some aggregates, so I manually create them and the directory structure. I add something in one place, remove something else in the other – I’m pretty sure that eventually, it will work. Well, it did not. I took a few deep breaths and returned to the “What next?” section. We can see how the setup in the context of Rails looks or how we can change the events’ serialization approaches. But our next step now will be the initialization of a new Bounded Context, which can be done by a generator.
Let’s try it with the advertisements BC:
rails generate rails_event_store:bounded_context advertisements
After running this command from the CLI:
- structure of directories for a new module was created:
advertisements
├── lib
│ ├── advertisements
│ └── advertisement.rb
└── test
└── test_helper.rb
- config for class loading was added to the application.rb file:
config.paths.add ‘advertisements/lib’, eager_load: true
Where to start? Test maybe?
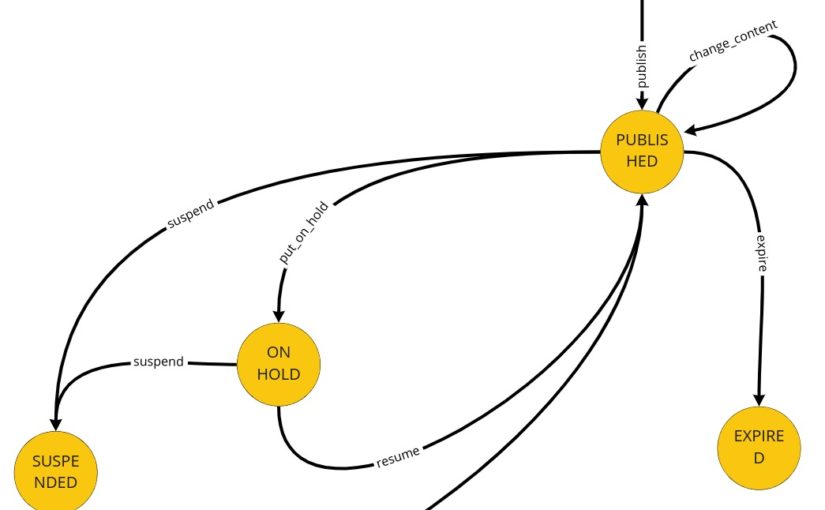
It’s time to write our first test. Let it be the test for advertisements’ content change. Let’s start with finding this piece in our model from Design Level Event Storming:

We can move that straight into the code. First, we should throw the command that should trigger aggregate’s business method execution. Aggregate itself should protect consistency, and after execution, we expect a specific event:
The asser_events method is a helper method that I’ve stolen from Arkency’s sample app. It reads events from the event store and checks whether there are the same as the expected ones:
The test, of course, does not pass, so now we should focus on implementing all the missing things. We can see that we are missing two commands and one event for sure. The first command – PublishAdvertisement – is in the Arrange section because if we would like to change the advertisement’s content, it actually has to be published/created.
The project’s default configuration supports class loading from the advertisements/lib/advertisements directory. Nevertheless, I like to keep commands and events in separate dirs. That’s why I create those classes in such a structure:
advertisements
├── lib
│ ├── advertisements
│ │ ├── commands
│ │ │ ├── change_content.rb
│ │ │ ├── publish_advertisement.rb
│ │ └── events
│ │ └── content_has_changed.rb
We need to explicitly tell Rails where to find them in such a case. We can do it by adding a few lines to the config/initializers/zeitwerk.rb file:
Now we just have to implement all those classes:
- PublishAdvertisement command:
- ChangeContent command:
- ContentHasChanged event:
We see that it’s still red when we run the test because we still miss commands handling and the aggregate that would throw the event. So let’s start with the handling of the commands. We will keep handlers in the advertisements/lib/advertisements.rb file:
Those examples show exactly how, in general, handlers should work. We should load an aggregate there, and then execute the business method.
Now we have to register our handlers on the command bus, and we can do it in the RES config file (config/initializers/rails_event_store.rb):
When we get back to the handlers themselves, we see the two last missing pieces: the aggregate and the repository.
Let’s implement the repository first (advertisements/lib/advertisements/advertisement_repository.rb):
You can notice here that RES via AggregateRoot class gives us an API for the repository. e can use that repository with the name of the events stream then. Theoretically, we could use this repository directly in handlers, but personally, I prefer having dedicated repositories per each aggregate. Mostly because I would like to have a coupling to the “framework” on the level of handlers. Thanks to this, we keep persistence details on the lower level.
By the way, you can also see here how the idea of event sourcing works. First, we pass a new object (Advertisement.new), the stream’s name, and a block/lambda. Then under the hood, events for the given aggregate’s ID are fetched and replayed on this newly created object. Finally, the given block is executed, which usually means the business method of the aggregate.
OK, so now we are almost there. The only missing part and the cherry on top is the aggregate’s implementation:
We have here business methods that protect consistency. Moreover, we throw events here.
What you see below business methods are event handlers in the aggregate context. According to RES’ convention, they start with on and then there is the event’s name. We’ve changed the aggregate’s state in those methods. We’ve done it this way because we want to separate responsibilities of running business rules and the state change. And that’s awesome!
Now let’s try to run the test one more time…
Hurray!!!
I would like to remind you the test and how it looks:
Actually, a single, specific line:
Please notice that we are expecting an event with the new content here. Now recall: do we keep this content in the aggregate itself? No. And that’s actually the most “mind-blowing” thing – we do not need advertisement’s content of the advertisement ;). The content is a view in our case. It’s needed only for reads. We do not have any business rules that require checking the content’s value. The only somehow connected rule is the one which says that only the author can change the content, and we guard it. As I promised: we can sum this up as “CQRS in action”.
The one for the road
Can I ask you now for a bit of love <wink, wink>? Actually, a star will also work 🙂 just take a look at the project’s code and hit a star if you like it:
https://github.com/stolarczykt/DevMountJob
If there’s one thing you can do today then please do yourself a favor and visit this repo and check how things are implemented with every new post. Just dive in there, clone it, run some tests, run the app. In other words: play with it and have a great time. See you next time!
Subscribe to the newsletter, so you will be the first to get to know about new posts!