
We covered a lot of ground. We started with the domain description and mistakes that I’ve made. Then we did the Big Picture Event Storming (BPES) to get the helicopter view of the whole business process and its events. Finally, we split this process into smaller units in the latest post using the Process Level Event Storming (PLES) technique. Today we are going to propose some designs for our solution. We will use Design Level Event Storming (DLES) to achieve this goal. At the same time, this is the last post about Event Stormings and next time we will be implementing our system.
First of all, I have to admit something: I love abstract thinking, and hardly ever do I have problems with it but this time was different. I have surely been an excellent example of the novice in the Dreyfus model of skill acquisition, no question. I expected some simple rules, flows, and conventions while putting the context and the goal on the back burner. I was looking for some notation at a push. All of that combined with my internal need to name things and abstractions, made me feel pretty confused. Having spent many hours in Miro, trying to create some models, looking at some other examples of DLES, and a couple of calls with Lukasz and Mariusz, eventually, something “clicked”. Well, it turned out that on the Design Level, I should… wait for it… design ;). An Event Storming is a tool used to visualize the business process, and there could be different designs supporting this process. That being said, there are different approaches to visualize those designs. We can choose/create notation or convention based on the project context, the workshop’s goal, or our preferences. The most important thing here is to visualize and propose the model that we think suits our needs best. That’s the difference between PLES and DLES. In the PLES, we were focused on processes, how they should work. Now on DLES, we should focus on models that support those processes. I just couldn’t get it.
The matter of taste
When it comes to modeling, let’s think about how we can use our sticky notes to do it. I’ve seen a couple of different approaches. I want to show you one that I’m going to use here and a few others so you can compare them.
Let’s start with a go-to book when it comes to Event Storming by Alberto Brandolini. Unfortunately, the chapter about DLES has just 10% of its target capacity, so there is not too much information about this workshop phase. The main message here is that we finally need to make decisions about the design. Even if we find something new, we need to develop an idea of how we want to solve that. It could be a bit hard, as in this part of the workshop attendees are often technical people, and we all know that we can talk about different approaches for hours. Nevertheless, we need to focus on proposing some solutions that support our business process.
In DLES, we introduce a yellow sticky note which indicates an aggregate. Brandolini suggests postponing naming it, and I tilt to this suggestion. Sometimes the first name “hides” the actual responsibility of the aggregate. Regarding the general approach in this part of the workshop, Brandolini presents a slightly modified version of the image we’ve already seen in PLES:
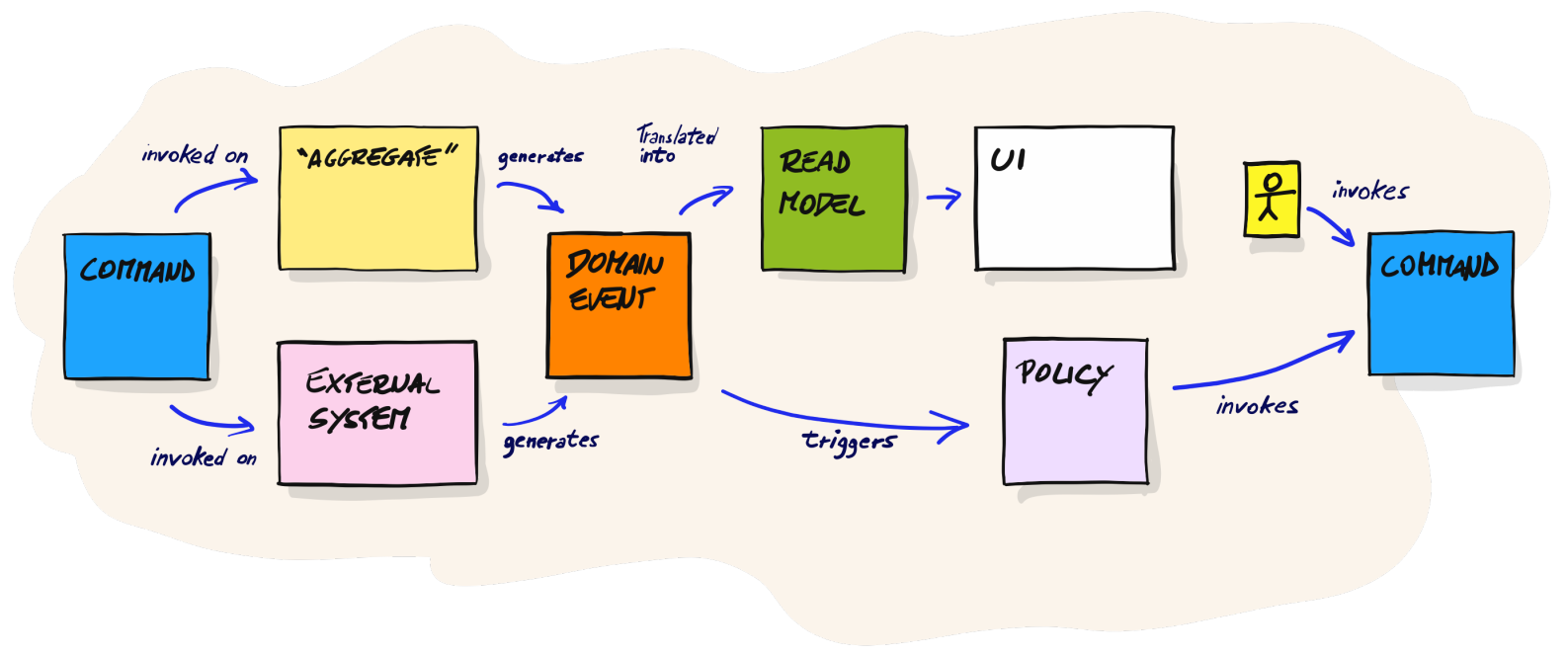
I think it’s a good moment to share some of my thoughts now. There is not too much said/written about DLES in the book itself, and mainly this picture drew my attention. Unfortunately, I fell into the trap of using this picture as a schema to modify my artifacts from PLES. In other words: I wasn’t thinking about creating design but about putting a yellow sticky note into processes. I think I’m not the only one who was trying to do it this way. When I was looking for examples of DLES, I often met PLES artifacts/thinking with one extra sticky note. That’s why it’s a good idea to participate in the workshop with an experienced facilitator who can explain the difference between DLES and PLES.
Finding aggregate boundaries or proposing other designs/models in places where there are no aggregates will be my goal in DLES. That’s why I will use the notation I used with Lukasz in one of the previous projects but bear in mind that you can modify it to your needs. You need to visualize your models in a way that is easy to understand, even if you get back to the board after some time. It’s you who are going to implement those models, so everything has to be straightforward for you and your team.
Let’s get back to the approach I will use here. In general, I want to gather business rules, commands, and events that “occur together”, no matter where they are in the process (in PLES). I also intuitively know that I usually have some model that aggregates those elements together. That’s why most cases will look as follows:
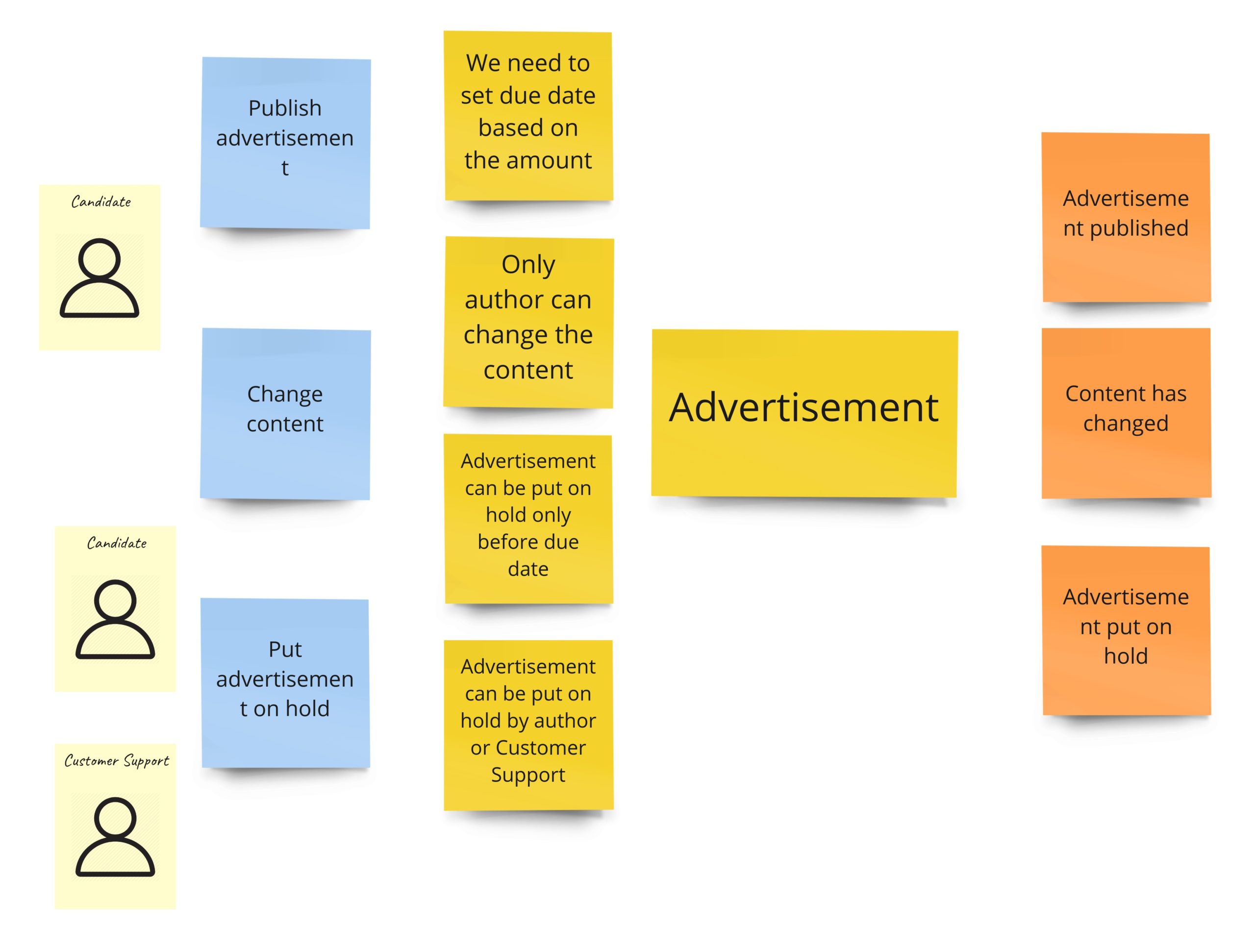
From the left: we see commands, then business rules, then an aggregate, and finally events that are thrown by the aggregate.
Another approach I’ve seen lately is the one where you have events below the commands. Thanks to that, we can have commands ordered by the time when they occur. So, for example, in this approach the previous case with the advertisement, we could model as follows:
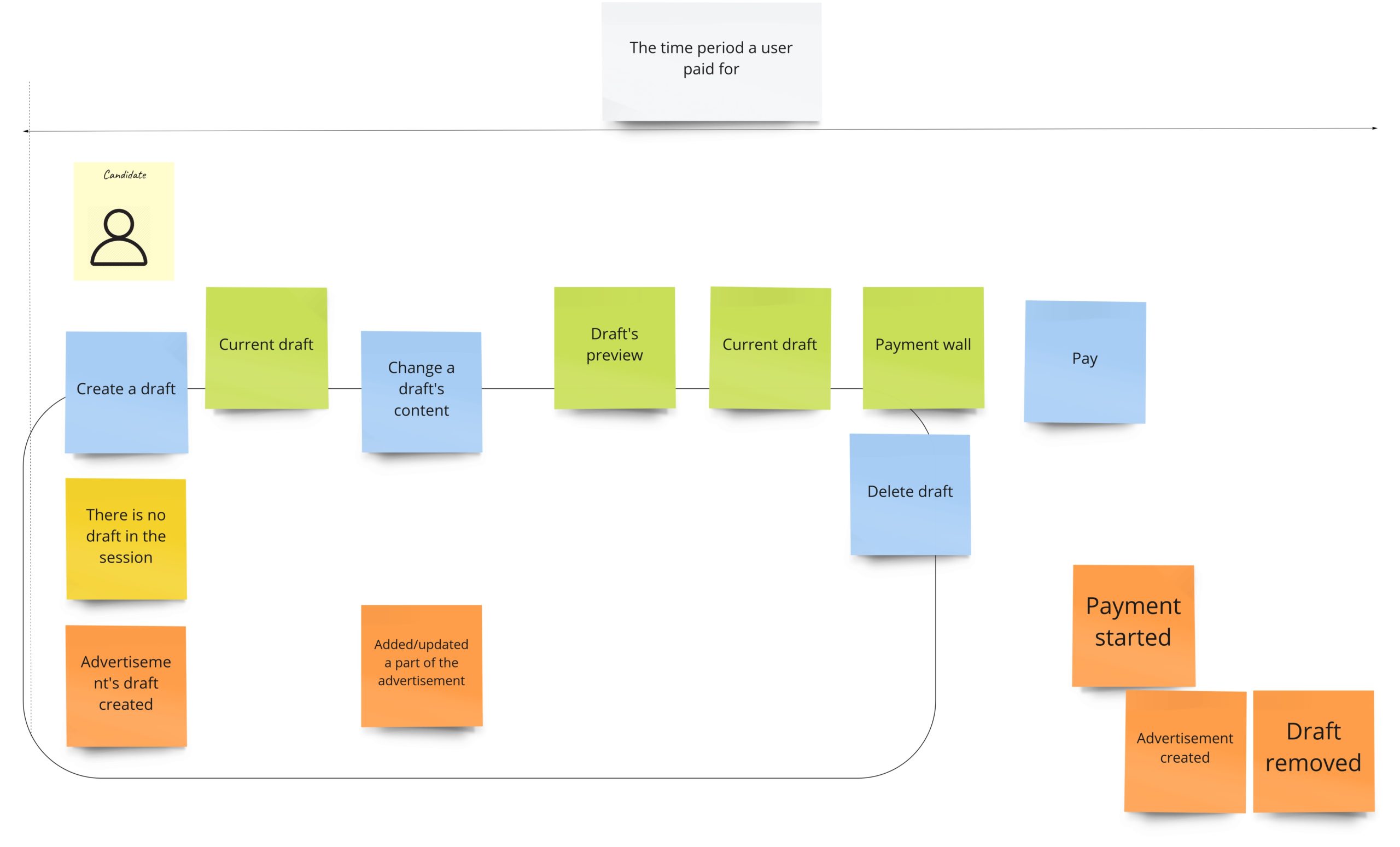
You can see the rectangle that more or less shows the aggregate boundaries, so we know which commands and events are connected with it.
The different approach I would like to show you is the one from the ddd-by-examples/library repository. Jakub Pilimon and Bartlomiej Slota use the Example Mapping in their DLES:

And the final result looks like that:
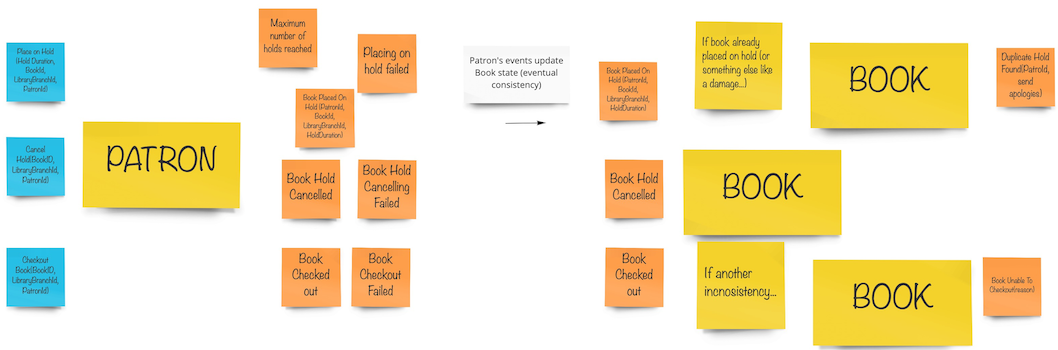
The last technique I would like to mention is the one I’ve spotted on Mariusz Gil’s Miro boards. Mariusz takes modeling a step further, and instead of presenting boundaries, he literally writes code entwined with sticky notes of commands and events. It causes a wow effect, as you can see the code even before sitting to your IDE. I encourage you to take part in Mariusz’s workshops so that you can see this approach in action.
Let’s get this party started
Now, after discussing all those approaches, we are going to do some work. Finally, we want to propose models that, based on our current knowledge, support processes we defined in PLES.
Advertisement’s preparation
Let me remind you how this process looks after PLES:
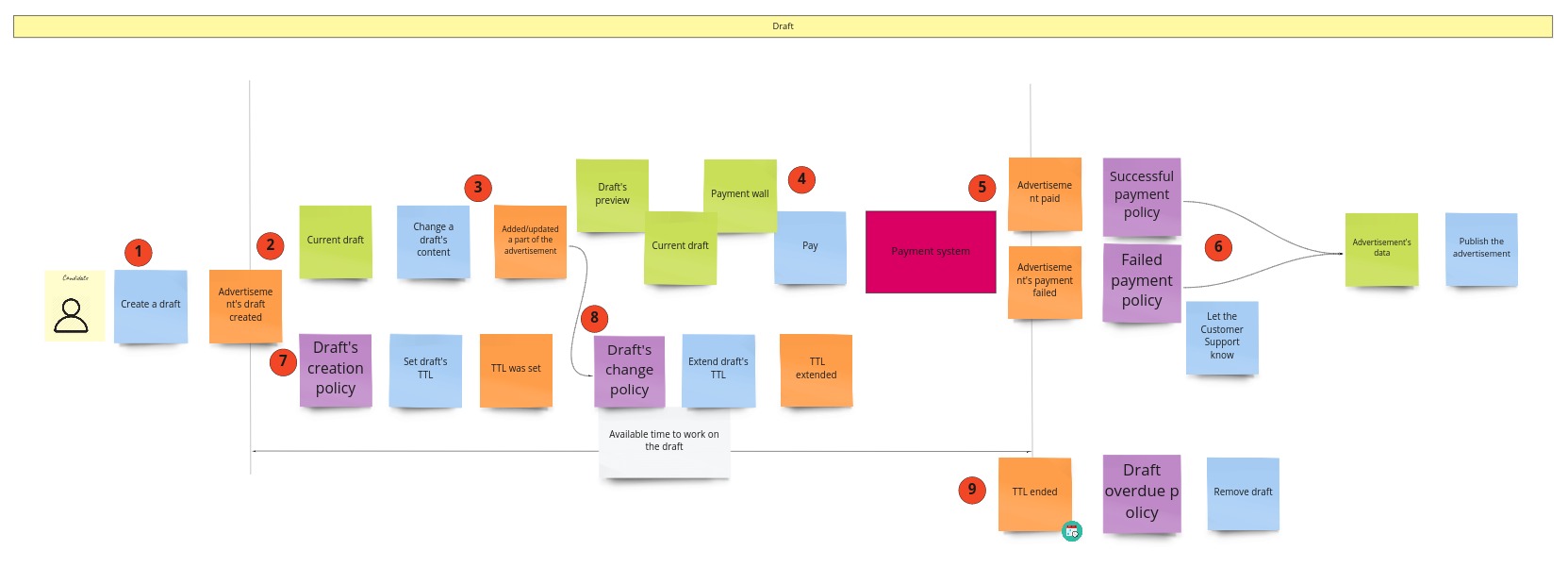
I can tell you that you will witness quite a revolution here. Initially, I was thinking about some model of a draft. I wanted to support situations when the user starts filling up the form, leaves it for some time, and gets back to it after a few hours/days. Keeping a draft would prevent starting from scratch. I assumed that I needed some object here that would react to content changes, and if there are none, it will expire after some time. I also had another requirement saying that a draft should work for both: logged-in and logged-out users. It means we would identify drafts based on the id kept in cookies. I did not require support for multiple browsers/computers. Given all that, when I started to design the model I realized, that:
- we need to create a read model of the draft on the backend
- we need to refresh this model each time a user changes its content on the UI
- we need to remember to remove it from DB when there are no changes from UI
- we retrieve the draft for the user based on the value kept in the UI/browser
Can you spot what’s wrong here? Firstly, if the UI/browser controls the whole lifecycle of the draft, why do we even need it on the backend? Secondly, all that functionality could be done by a few lines of code on UI with local storage support. What’s interesting here is that we can support the process without the explicit model of the draft. We can just use what the browser gives us out of the box.
When we don’t care about the draft, we can skip everything that is before the payment. When it comes to the payment itself, I have just two requirements:
- no matter if the payment succeeded or failed, the advertisement has to be published. It means that we can publish the advertisement when we start the payment process. This decision simplifies the whole process.
- if the payment fails we need to send the information about the failure (some details) to the Customer Service
When I wanted to follow the notation I described in the first chapter, I got something like this:
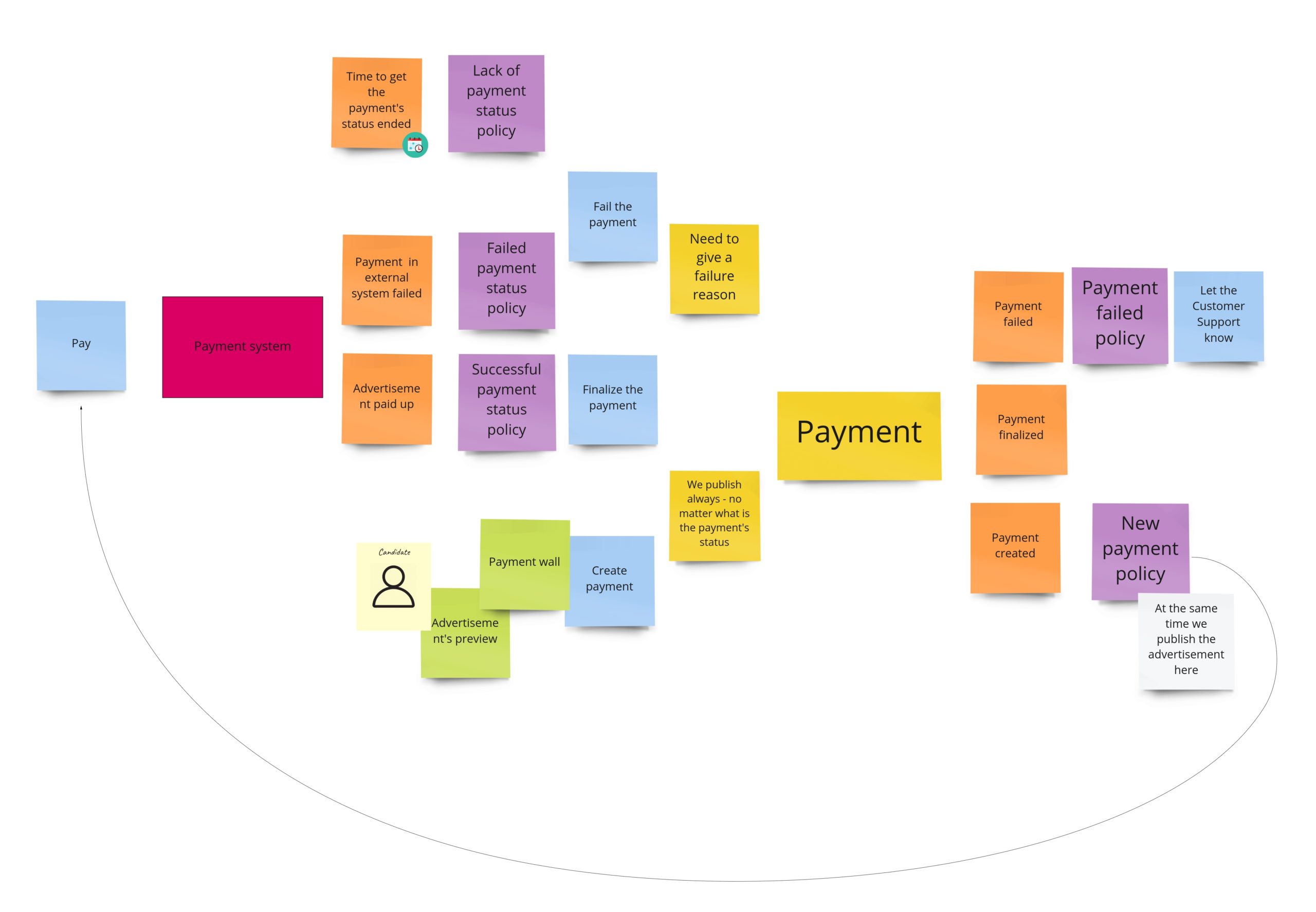
Some of the commands that change the payment’s state are triggered after responses from the payment system. Moreover, we request the payment in the external system after we have created the object of payment. Unfortunately, the readability is not so good here, so in DLES, I decided to not stick to my general notation but to show the chronology:
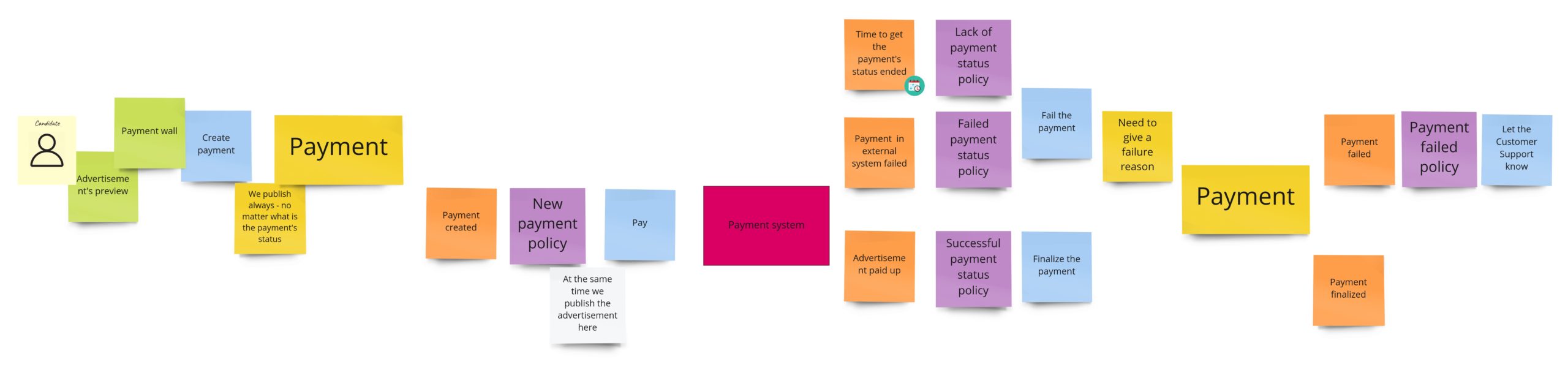
The difference here is that the sticky note with payment’s aggregate occurs twice. So now it’s easier to see when we change its state. I write about “aggregate” here, but conceptually, it would be the process manager if I were to publish the advertisement only after successful payment. Nevertheless, in both cases, I would probably call it the “Payment”.
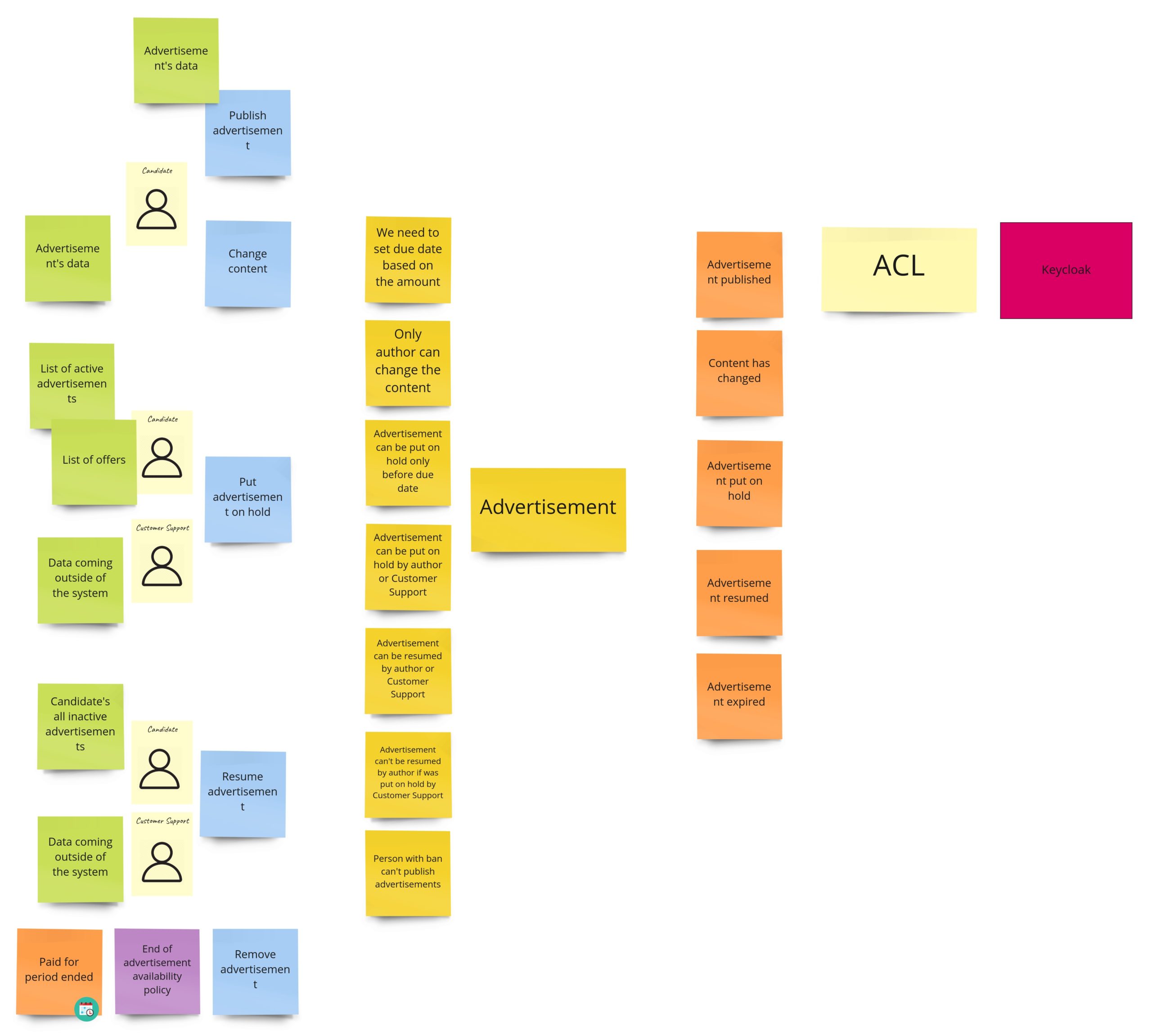
Publication
During the PLES, we came up with such a publication process:
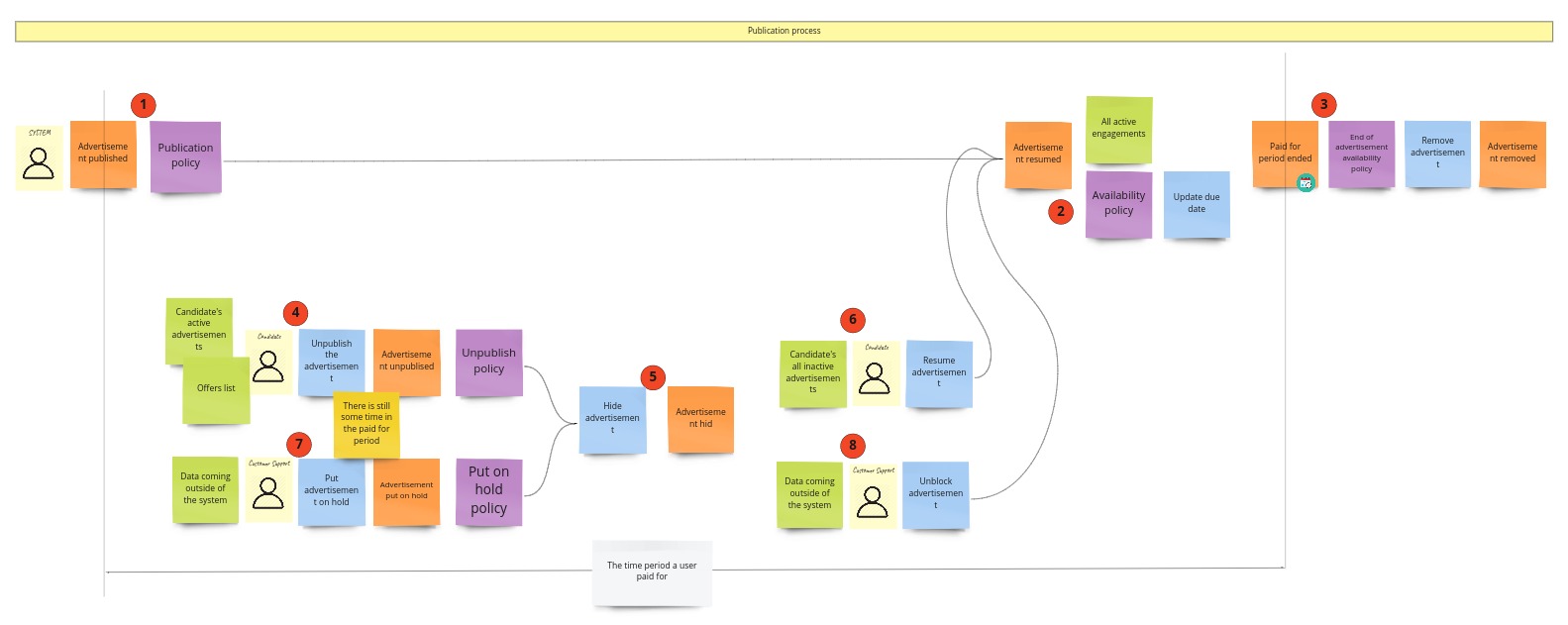
We call it “publication,” even so it’s about hiding/putting on hold and resuming the advertisement. Maybe you somewhere have seen a similar process under the “availability” name. It’s pretty generic and occurs in this or slightly different form in most of the domains. I’m still not convinced of the “publication” as a name of the Bounded Context, so it can change when I start the implementation.
When it comes to the model of this part, I would see it like this:
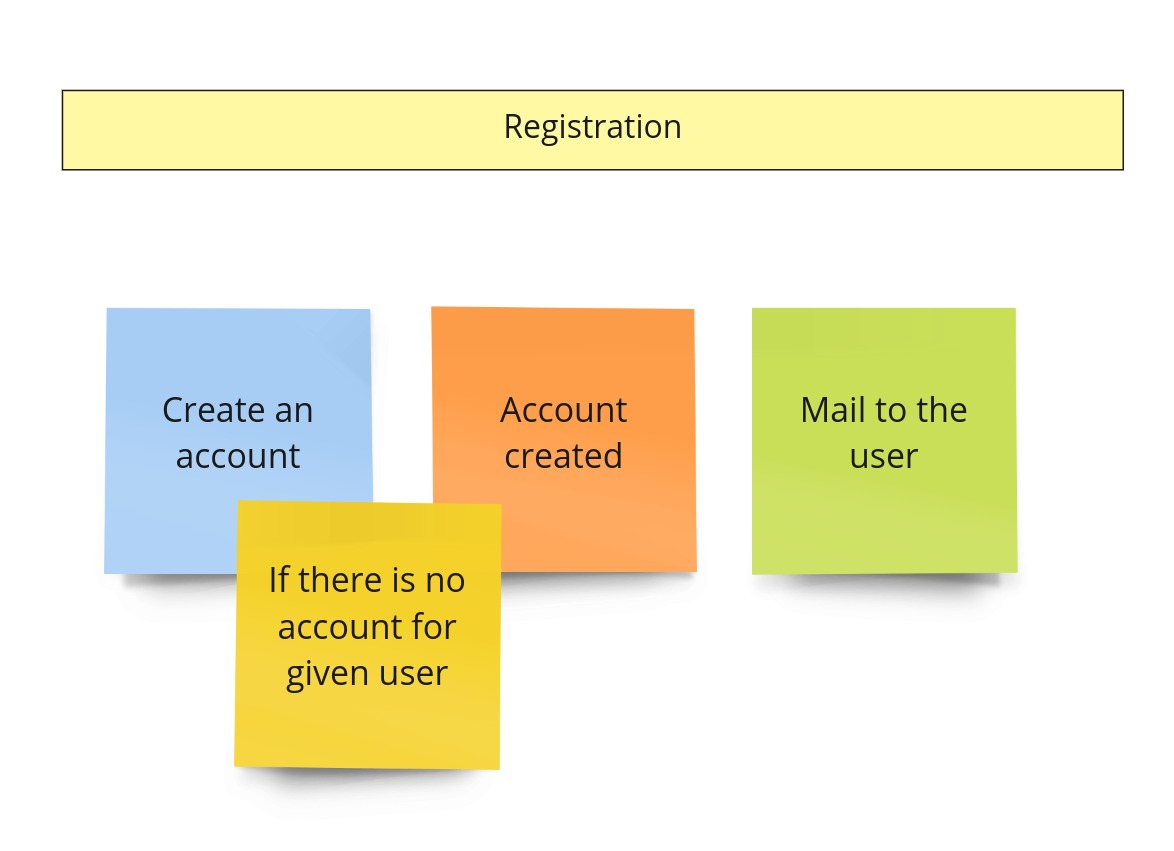
Registration
In the previous image (the one with the advertisement’s model), you could notice such a piece:

On the other hand, after the PLES, we had something like this:
You might have noticed that there is usually something more than just the “registration”. This part of the system usually is responsible for user management and grows to a whole module or even a separate service. Initially, I was also thinking about it this way. For example, I was thinking about the case where the Bounded Context responsible for banning recruiters would also communicate with this module.
Those “accounts” modules are often developed from scratch, have additional integrations with external services, and keep users’ data. At the same time, such a module exposes API, used by most services in the company. Even though sometimes the user management itself is delegated to some external service. We could model this case like that:
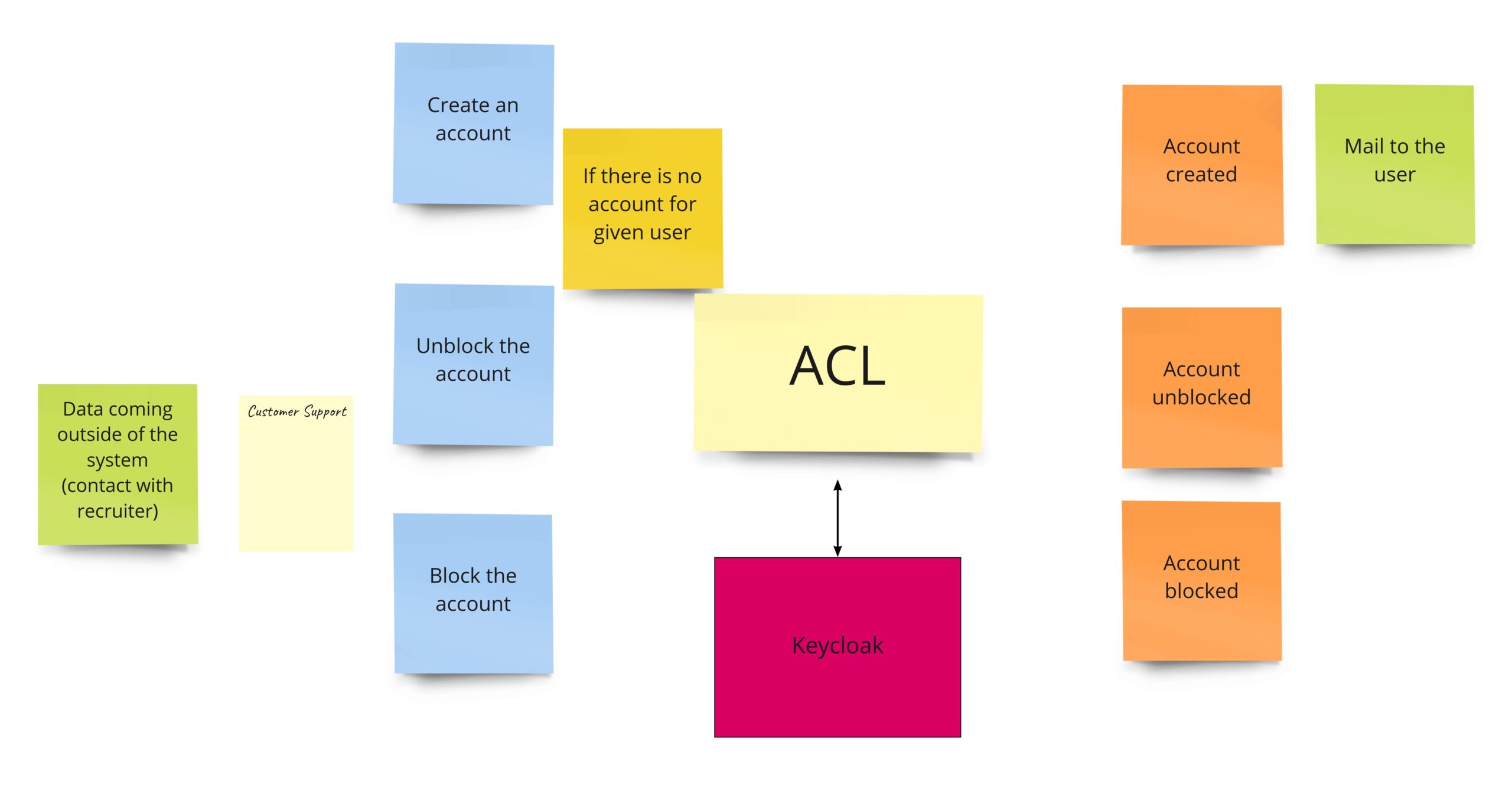
Nevertheless, this approach has some downsides. First of all, it’s an additional module. Secondly, API has to be implemented in such a way that all other services can use it. That’s why I decided to use another approach in this project. I will probably use something like Keycloak, letting other modules integrate “directly” with it. But, of course, as we don’t have control over Keycloak’s API, each of the Bounded Contexts will have a tiny Anti-corruption Layer (ACL). The advantage of such an adapter is that it’s tailored to BC’s needs. Thanks to that, “Publication” will use the registration functionality, and “Banning” will use only block/unblock functionality.
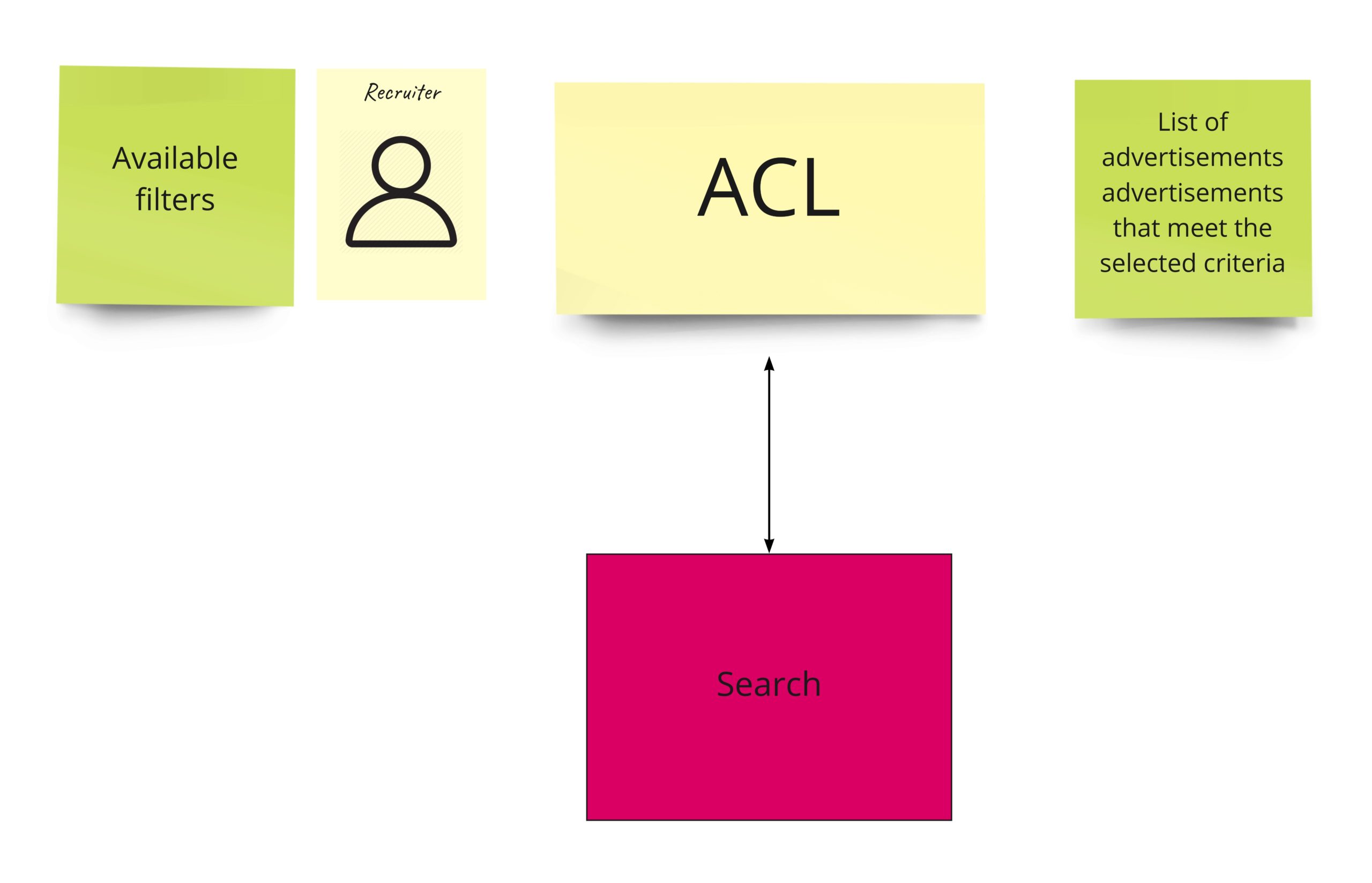
Search
For now, we will have here just an ACL that will communicate with the external service. Communication will be synchronous here.
Offering
When recruiters find an exciting advertisement, they can make an offer to the developer. The most important rule here, the clue of my whole idea, is two things:
- a recruiter has to accept all developer’s requirements,
- a recruiter can make only one offer per advertisement.
Other rules specify primarily who and what can do with the offer. For example, it means only the recipient can reject the offer or add it to favorites. So our offer model could look like this:
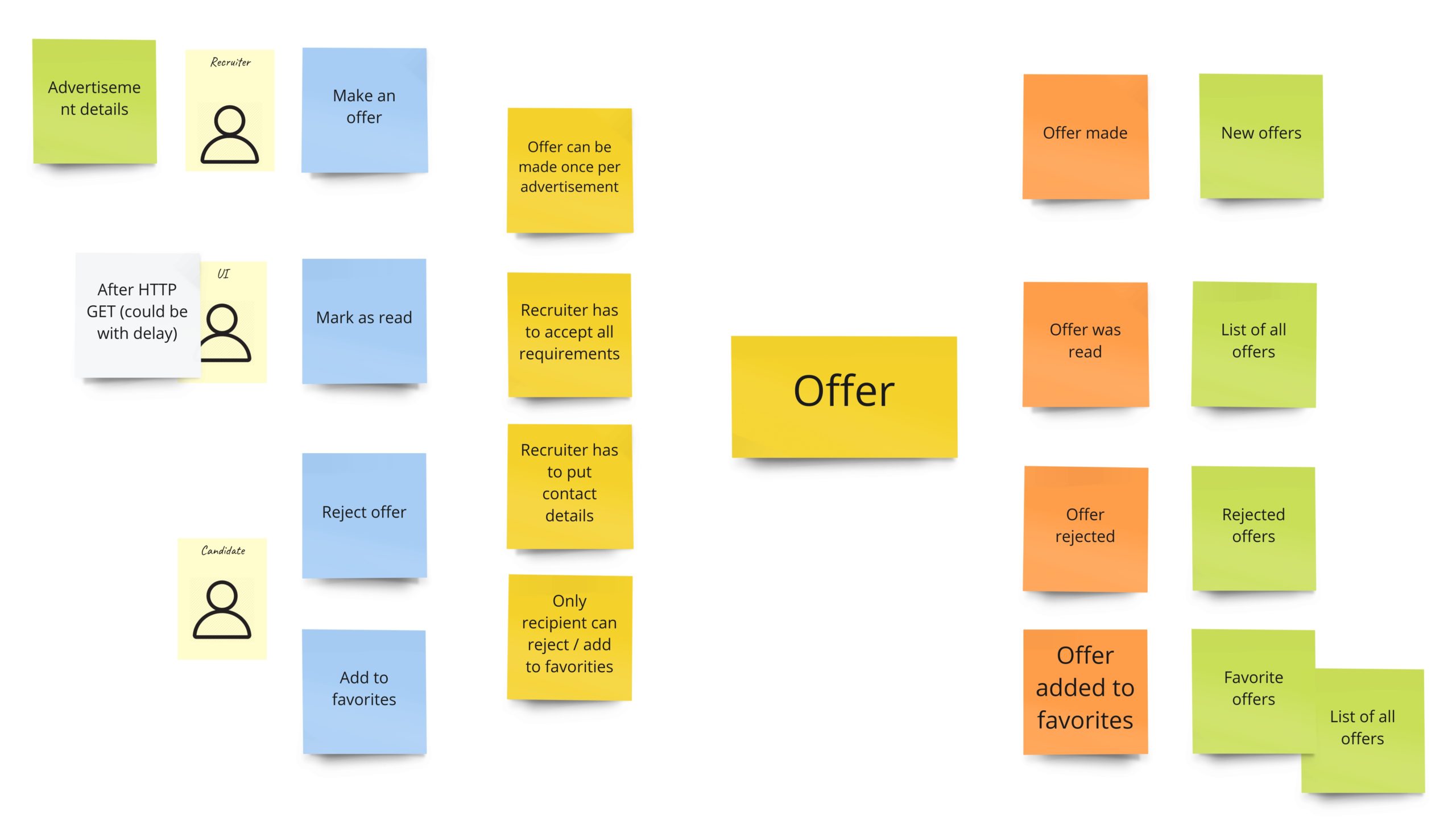
“Self verification”
In the first post about Event Storming, you may recall that I totally messed up the idea of this part. I was using events that I had no access to. I mean, those were, in fact, external system events that occurred outside of my domain. Fortunately, it came up quite early. During the PLES, I knew that I just needed to query the external systems about whether the developer solved any tests.
When it comes to the design, it looks like we need two things here. First is a simple CRUD for the links (URLs) to tests in the external system. The second is an integration with the external system that can query it on-demand and give us the list of tests solved by a specific developer. Having those two parts will allow us to manage views with the developer’s badges.
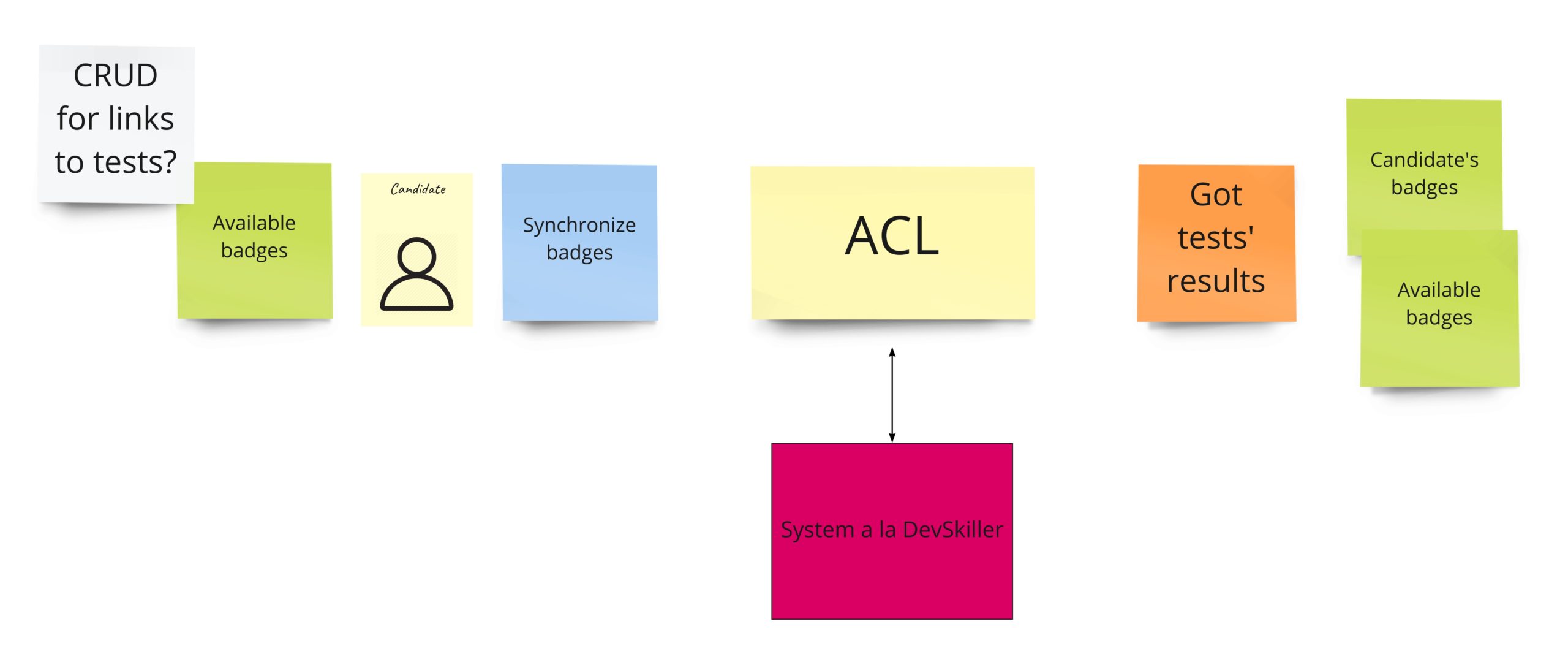
Banning recruiters
Banning is for sure a process that I would skip in the MVP phase. But, nevertheless, we’ve had a lot of discussions about this part, and what’s more, it has one interesting quality: in general, it’s actually a consumer complaint. So that’s why you may already see this process in other domains. Take a look at how I designed it during the DLES:
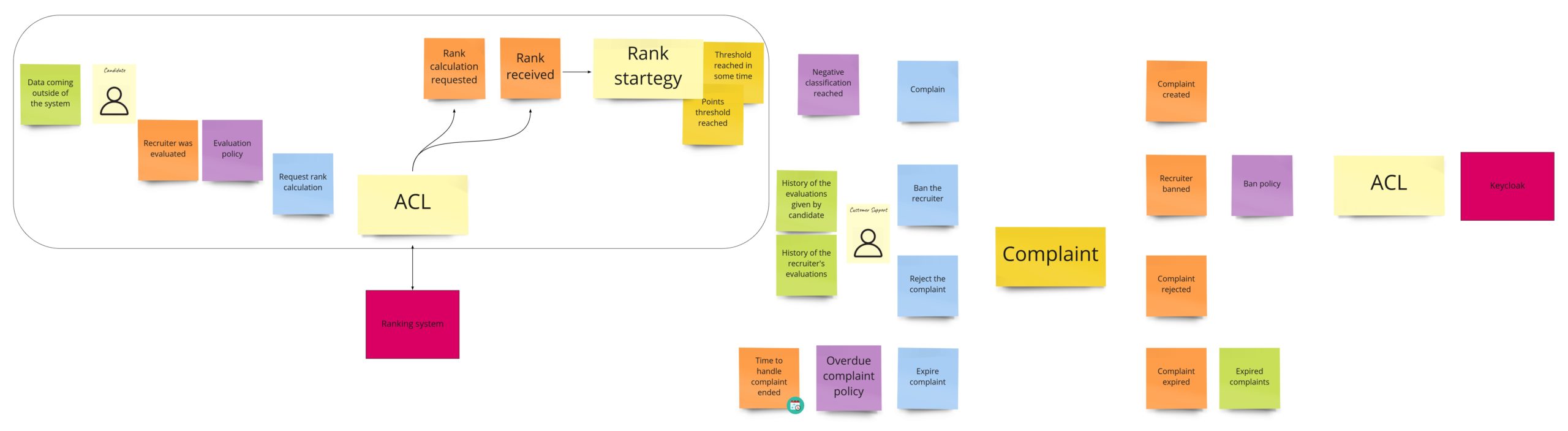
We can spot two parts here:
- On the left – probably some kind of process manager, as it’s quite an asynchronous process. It can be initiated by a developer, who felt scammed in the recruitment process, or contrary – wants to commend the recruiter. The developer fills up the “review form”, where they rate a person who made an offer. We send this review to an external rating system, which recalculates the overall recruiter’s rank. When we get the response and see that the rank drops below some threshold, we create a complaint.
- On the right, we have the “complaint” itself and its state management.
Even though we call this part “banning”, you can see that we have two concepts here: ranks and bans. We could split them into two separate contexts, but for now, we are interested only in negative ranks, so we will stay with a single context.
Food for thoughts
As developers, we design every day. We may not be aware of it, but each method, each class, has some design. Unfortunately, we rarely visualize it in any form. Instead, we keep it in our heads, where we build huge models and connections between them. It seems that we understand all that entanglement pretty well, as we notice many implementation details and business rules. But, in fact, all that is usually a misleading impression. We realize that when we start to “dump” all those models from our heads to code. There is always something that doesn’t fit.
Design Level Event Storming gives us the advantage of experimenting with each idea that comes to our mind. There is no doubt that we have forgotten something on the way back from lunch ;). Our models are still on the board in the form we left them there. We can move sticky notes around, check different approaches. Thanks to that, the final models that we’ve decided to move to the code are more thoughtful. Of course, our models can still change during the implementation, and we even have a name for that: modeling whirlpool. But those changes will usually result from a better understanding of the domain than the fragility of our memory. In such a case, we can get back to the original board and evaluate a new idea by moving some sticky notes again. Artifacts of DLES are ideas for models. They are not etched in stone. Sometimes, it’s also good to implement some prototypes during the workshop to have a closed feedback loop.
That’s all that I have for you about Event Stormings. We went through all its stages, and now we are going to move models to the code. In the next post, we are going to start doing it on our fancy tech stack. I may surprise you with some of my choices, especially that it will be an “all-in” approach: DDD, event sourcing, and CQRS!!! Stay tuned! Don’t miss it and subscribe to the newsletter!